

Shader Execution Reordering
We have seen a big transition in real-time graphics where more and more games use ray tracing and even path tracing. These rendering techniques often lead to workloads that are difficult to predict because of the highly divergent paths taken by light rays as they bounce through a scene. This could be a significant performance hit on the GPU because threads execute in groups that I will refer to as waves (called warps on NVIDIA, wavefronts on AMD, and subgroups on Intel), where generally all threads in a wave execute the same instruction in lock-step. Overhead occurs when control flow diverges because both paths of a branch must be executed sequentially. Aside from that, incoherent memory access patterns prevent optimal cache usage and memory coalescing.
To improve execution and memory access coherence within waves, DirectX Raytracing (DXR) Tier 1.2 with Shader Model 6.9 introduces Shader Execution Reordering (SER). SER opens the opportunity for application developers to suggest how to dynamically regroup threads across waves based on user-defined coherence hints and/or information about the traced ray. The specification defines that this can only happen in a ray generation shader on a best-effort basis left to the implementation. This coherence hint should be the same value for workloads that are expected to take the same divergent path and load similar data so they can be grouped and executed within the same wave, potentially improving both execution and data access coherence.
How does it work?
The HitObject type has been added to store the context of a ray after traversal. It can replace calls to TraceRay() using HitObject::TraceRay() or subsume the results of a RayQuery using HitObject::FromRayQuery().
There are three ways to indicate how threads may be reordered. The simplest way to request reordering is by passing a HitObject as an argument. In this case, the driver may use properties of the HitObject such as the hit position or hit group index to group similar threads and improve execution coherence.
Additionally, MaybeReorderThread() can take an optional coherence hint. This coherence hint is defined as a user-provided uint value along with a bit count specifying how many bits should be considered for reordering, starting from the least significant bit. The most significant bits in this range have the highest reordering priority. It is also possible to provide only the coherence hint without passing a HitObject instance (source).
void dx::MaybeReorderThread(
dx::HitObject HitOrMiss,
uint CoherenceHint,
uint NumCoherenceHintBitsFromLSB );The specification however does not guarantee that MaybeReorderThread() will perform any reordering, the minimal allowed implementation is a no-op.
The sample below demonstrates how to use the new HitObject for pipeline ray tracing. It demonstrates the separation of the tracing stage via HitObject::TraceRay(), followed by reordering and finally executing the necessary hit or miss shaders bound via the shader binding table using HitObject::Invoke().
dx::HitObject hit = dx::HitObject::TraceRay(...);
dx::MaybeReorderThread(...);
dx::HitObject::Invoke(...);This next sample showcases how to perform a ray query using the existing RayQuery API. A HitObject is created from the committed hit in the RayQuery, which is then used to invoke dx::MaybeReorderThread(). A HitObject created from a RayQuery has no associated shader table entry, so calling Invoke() has no effect.
RayQuery<T> rayQuery;
rayQuery.TraceRayInline(...);
dx::HitObject hit = dx::HitObject::FromRayQuery(rayQuery);
dx::MaybeReorderThread(...);Note that MaybeReorderThread() is only available in ray generation shaders, even when using RayQuery.




Experiments
We ran experiments on different GPUs to see what the impact of adding Shader Execution Reordering would be on our Pipeline Path Tracing benchmark. We compared no reordering against two approaches: reordering based on the material index, and reordering using a “properties mask” that encodes certain material properties such as alpha masking, whether the material follows a significantly different code path (e.g. water or terrain), and how many layers the material has. This properties mask is obtained through a buffer load using the material index.
We tested the following GPUs at the given driver versions:
- NVIDIA GeForce RTX 4070 Ti at preview driver version 590.26.0
- AMD Radeon RX 9070 XT at driver version 32.0.21007
- Intel Arc 140V (MSI Claw 8AI+) at driver version 32.0.101.8136
Scores shown below are the Raytracing scores from the Evolve pipeline path tracing benchmark runs with Shader Model 6.9 and HV 202x. "No re-ordering" means that HitObject::TraceRay() is called without MaybeReorderThread().
NVIDIA
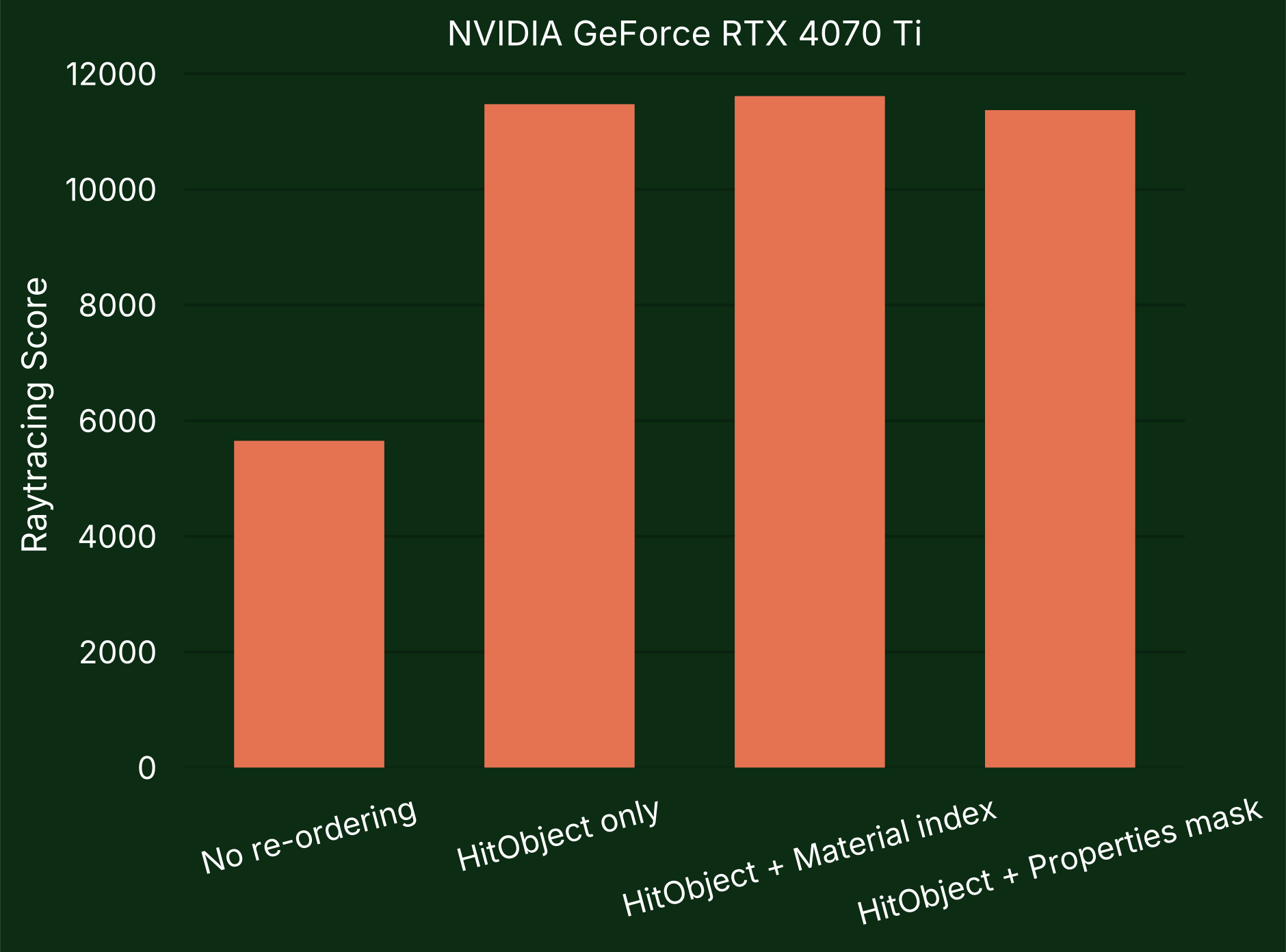
On the tested NVIDIA GPU it appears that reordering based on the material index seems to be the most effective.
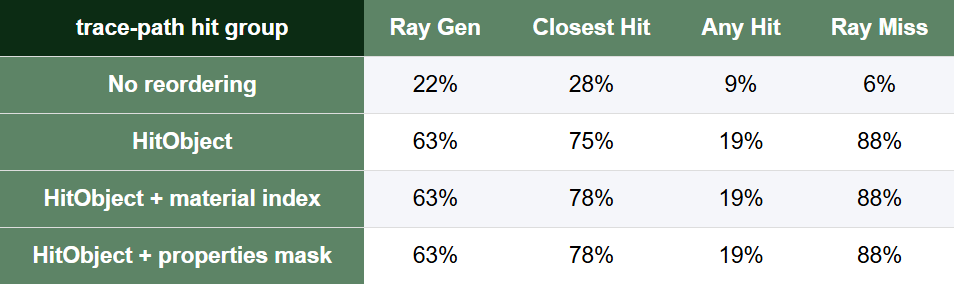
In Nsight Graphics the wave coherence of the various shader stages can be visualized, when comparing this between the various reordering strategies used it becomes visible that reordering has a significant effect on wave coherence in the ray closest hit and miss shaders.
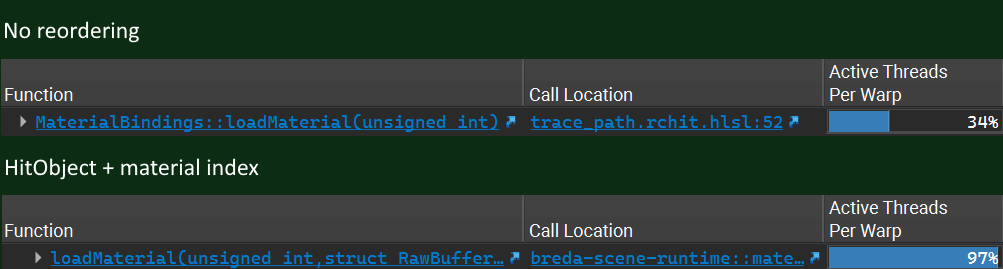
In the example below, you can see that when not reordering, only 34% of the threads within the wave execute the same instructions. When reordering based on the material this became 97% which resulted in a massive performance improvement since the #1 stall was texture loads.

AMD
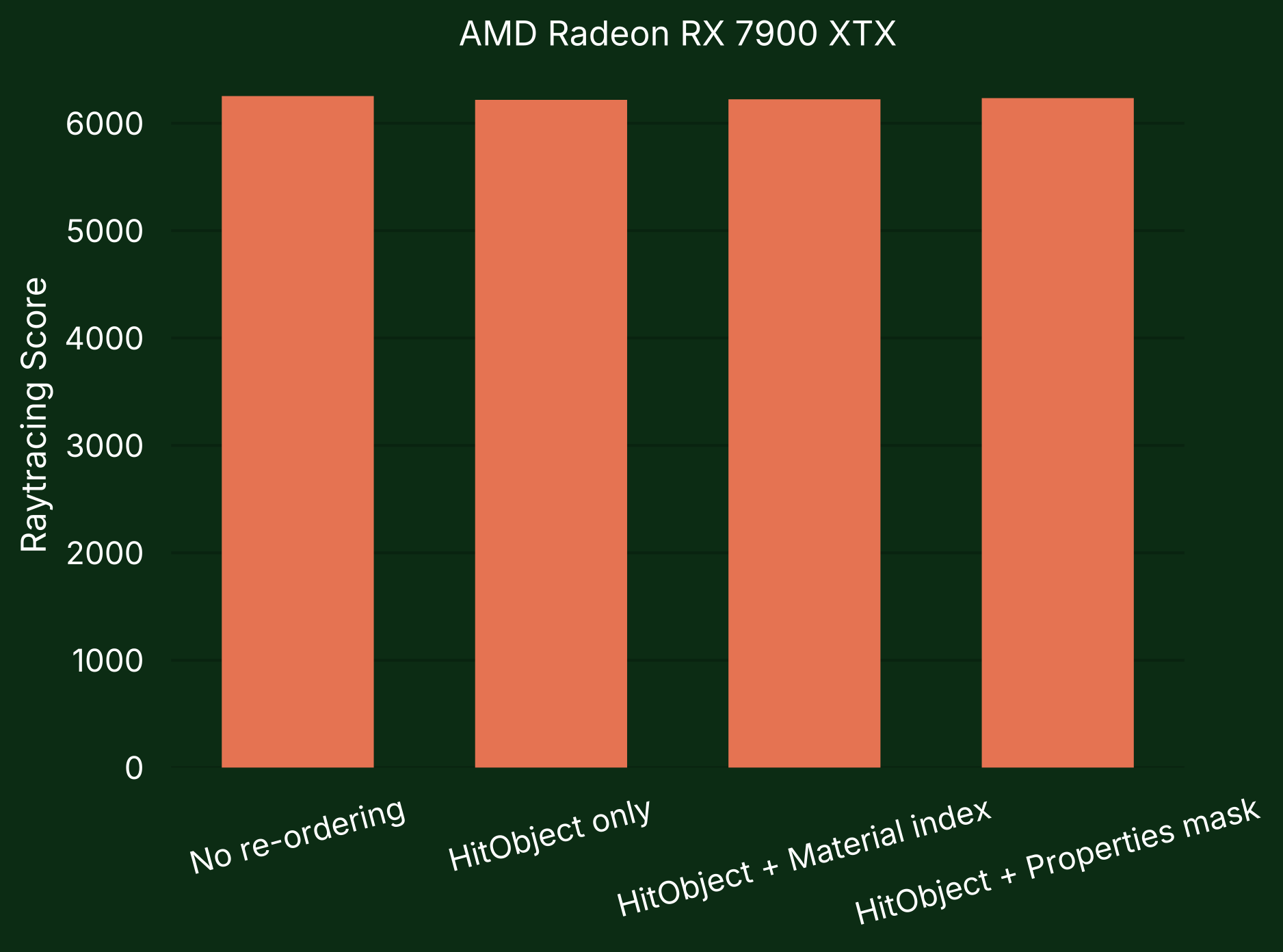
On AMD GPUs no performance difference was noticeable between the tested experiments. This is expected since they mention that MaybeReorderThread() currently does not move threads (source).
Intel
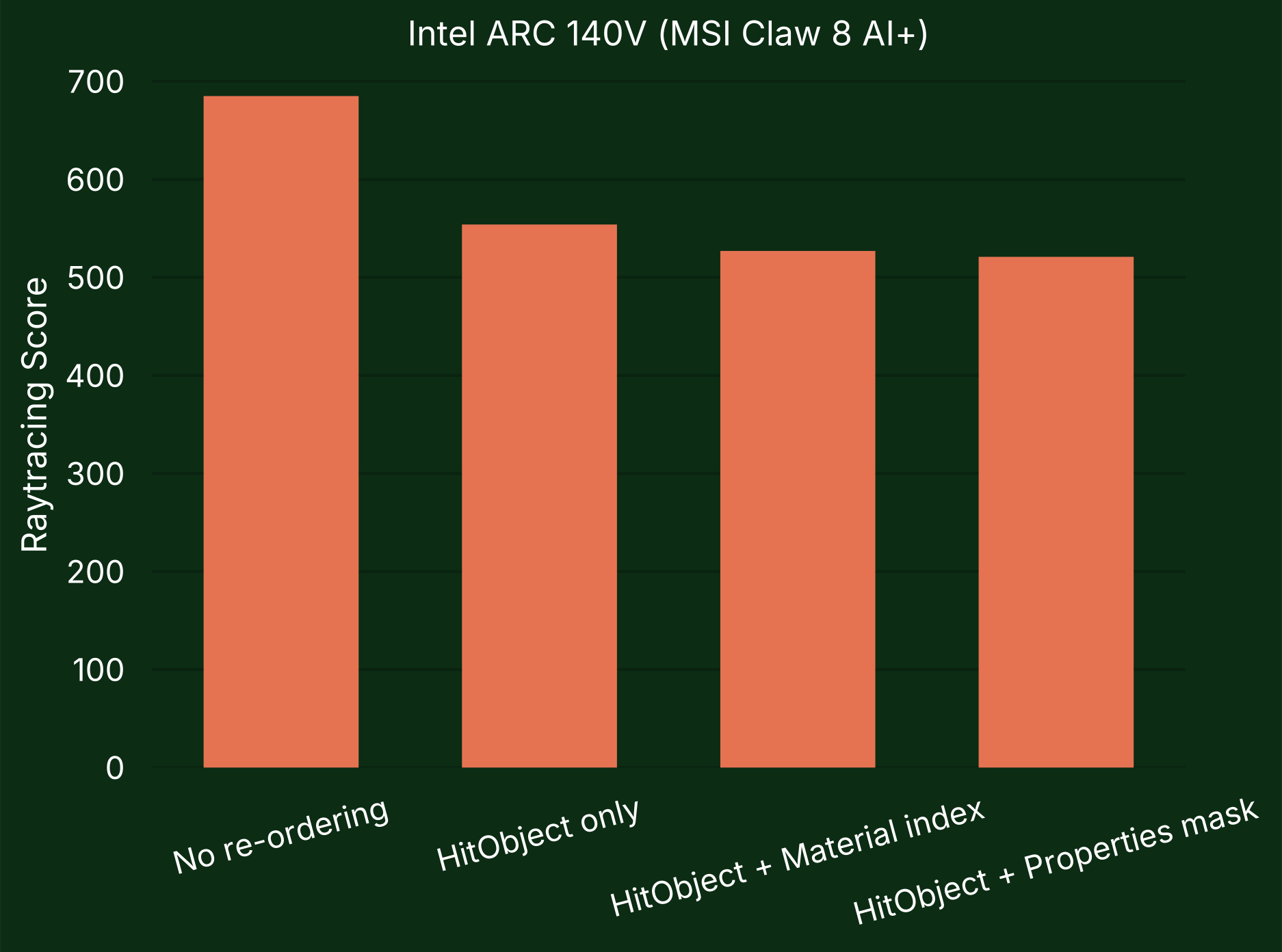
On Intel GPUs, Shader Execution Reordering does not currently provide a performance improvement. The ray tracing score was slightly worse than when not re-ordering when using the material index as a coherence hint, and lowest when the properties mask was used.




